本文共 5263 字,大约阅读时间需要 17 分钟。
随着产业发展,任何企业都会因为内外部环境的变化,驱使自己从经验驱动转向数据驱动。尤其是快速变化的互联网行业,传统经验快速过时,经验已经成为阻碍正确决策的绊脚石。随着用户的个性化需求越来越强烈,数据信息也变得海量,而且企业之间的激烈竞争和运营管理也越发复杂,这一切都彰显了数据分析部门的重要性。
根据IBM估算的数据和麦肯锡全球研究院的数据表明,19世纪和20世纪的人类生产活动,一共产生了50GB的数据;而在2011年,人类产生相同的数据量只需要两天。这么庞大的数据量,令企业的私有数据及数据分析能力成为了企业独一无二的资源。通过数据管理,对企业来说能够迅速降低制造和组装成本,提高净利润;能够实现产品创新,提高自己的竞争力;能够获得特定用户的行为特征,获得高附加值和溢价,等等。而Amazon、Facebook、Google等互联网巨头,都在通过大数据分析获益。
本文将讲述数据分析的原则和步骤,并讲述如何做出正确的趋势预估。
眼睛会骗人,数据也会
我们知道,由于观察者心理和生理上的原因,导致我们经常会出现视觉误差。我们一直都认为眼睛是感官中最能反映真实情况的器官,甚至俗话说“眼见为实”,但是眼睛却不止一次地骗了我们。例如我们看下面这几张图,就是最典型的视觉误差的表现。

图片中到底是白点还是黑点?

这个三角形是直立的还是平放的?
上面两张图是视觉误差的典型,我们再看看数据给我们带来的感知上的误差。
我们举一个互联网行业案例。
如果A网站的用户平均年龄是20岁,B网站的用户平均年龄也是20岁,我们能否得出一个结论:A、B网站的用户基本上都是同一年龄层的?而事实上,很可能A网站是一个面向大学生的细分产品,而B网站则是一个覆盖16~30岁用户的社交产品。这涉及均值、中位数、众数等不同数值的统计方法。
因此,我们如果单纯看表面数据,来推断我们想要的结论,那么数据有很大的概率“骗人”。因为样本抽样的误差、抽样方式的选择不同、数据分析方法的不一致,都会导致不同的结论,甚至能得出完全相反的结论。我们做运营的时候需要数据支撑,但是数据却把我们骗了。
接下来,我们需要明确数据的统计和分析原则,以及分析的步骤。
数据统计的原则
如果我们要问数据统计和分析有什么原则,至少这三条不可忽视:业务导向、清晰完整、可溯可比。
首先是业务导向,我们必须要清楚数据是用来指导业务发展的。数据分析的目的一定是“从业务中来,回业务中去”,业务导向会帮助我们在工作中找到关键点,并且将注意力都集中在解决问题的数据上。例如我们研究微博某日的DAU活跃情况,发现其出现了大幅增长(超过10%),因此我们进行逐层分析。

我们发现在这次微博DAU大幅增长中,最后通过拆分来源知道用户来自于Web登录用户的快速增长,其低频老用户使用Web登录大增19%,经过进一步研究,得知Web端当天做了一次针对低频老用户的登录有奖邮件召回活动,导致大批低频老用户回流。
而通过这次对关键指标的进一步分析,我们确定此次针对低频老用户的邮件召回活动效果非常好。
第二个原则,清晰完整。数据清晰完整包括四个要素:数据定义清晰、计算规则准确、数据来源明确和单位量级清楚。这四个要素构成了我们数据统计的基础表格,并可以在图表中清晰表示。
例如我们要参考某网站的一次运营活动的数据,我们可以看到该活动的报表有着明确的数据要素,能够做到清晰明了。
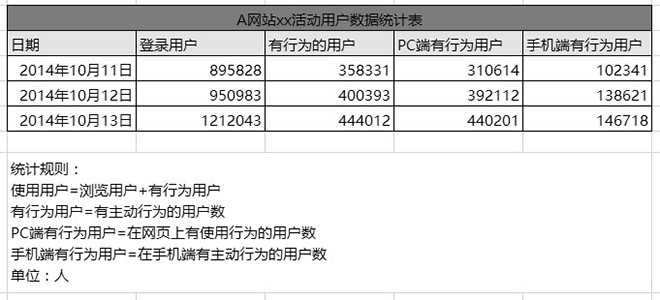
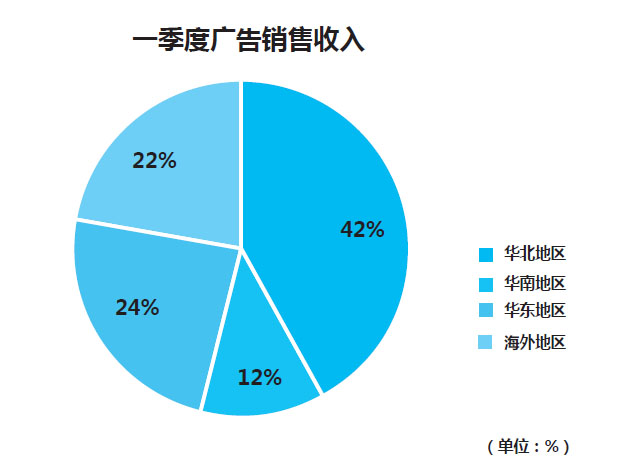
第三个原则,数据可溯可比。运营数据不能单独存在,单独存在并没有运营价值。例如某企业的销售额,通过横向对比同一时间段的不同区域,可以看出各地区销售情况的好坏。
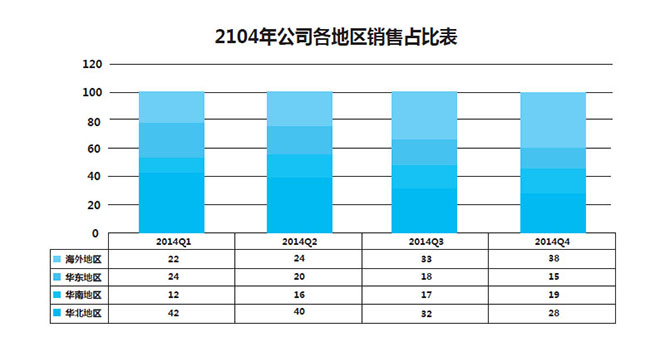
而我们对数据进行历史回溯的话,就可以和历史纵向对比,从而了解企业在不同时间段的经营状况。
数据分析五步法
获得了基础数据后,我们该怎么研究数据?一般而言,我们可以通过五步分析法进行简单的数据处理。
第一步,定义问题。明确需要通过数据解决的业务问题,尽量准确地表达问题,以及对数据对象进行定义。
第二步,收集信息。了解问题的背景,收集和整理关于要解决问题的相关数据。
第三步,选取分析方法。分析涉及的主要数据维度,为后面提取数据需求做准备。同时,选取必要的分析方法和分析工具(软件)。
第四步,数据提取整理。根据分析内容和分析方法,提出所需的数据指标需求。在实际分析中,要多数据、部分加工,来更好地支持分析的问题。
第五步,分析结果和结论。得出明确的分析结果,并且以正确的方式呈现。
下面,我们将通过一个虚拟案例来实践这五步分析过程。
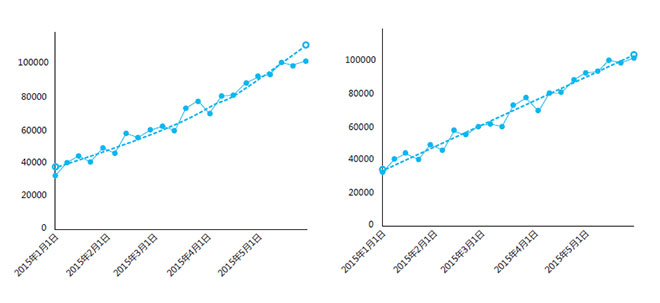
某网站是一个新兴的互联网O2O网站,根据内部数据分析,想要了解该网站未来三个月的日PV。
上面这一段定义了一个明确的问题,因此,工作人员通过后台收集数据,得出以下曲线。
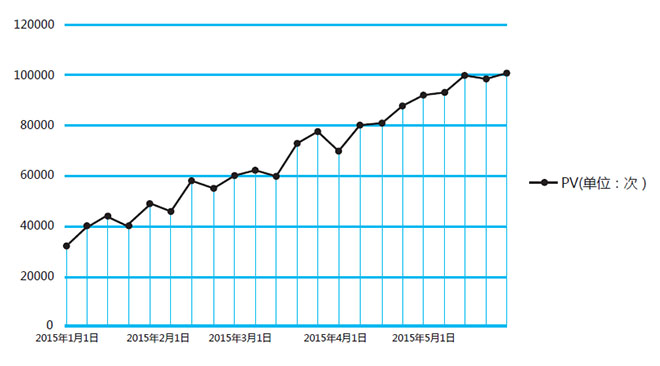
因为这个分析的目的是获得未来的网站发展趋势,因此,可以添加趋势线。图像是最直观地展示数据发展趋势和预测分析的方法,在Excel中就可以添加,常用的趋势线包括:指数,对数,线性,多项式,等等。

不同的曲线对应不同的形态:指数曲线有着增速放大的趋势,对数曲线有着增速放缓的趋势,线性曲线一般在没有明确的趋势时使用。
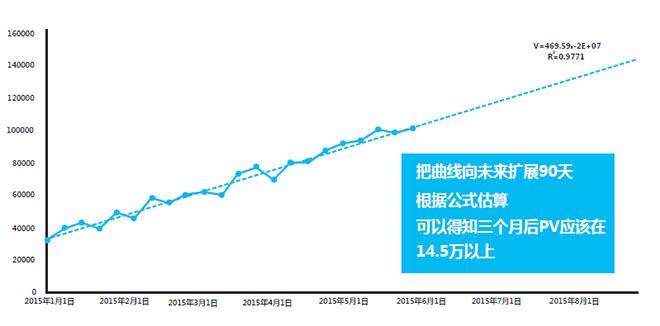
接下来我们对数据提取整理。我们可以把三种趋势线都在表格中表现出来,然后在选项中选择显示R²,R²是一个用来展示预测效果的系数,介于0~1之间,越接近1越准确。所以我们在选取趋势线的时候,应该选取R²值最大的趋势线。
那么在分析结果和结论的时候,我们就可以对线性趋势图进行预测,预测未来三个月的日PV值的方法如下图所示。
上面这个案例通过简单的工具(Excel)来分析简单问题(一个稳定发展的网站的未来预测),用来描述数据分析五步法的工作方式。
由于数据分析的复杂程度较高,大型互联网企业都纷纷建立数据分析部门来专业地进行相关工作。对于运营人员来说,更重要的是理解整个分析过程的逻辑,在需求(定义问题环节)到分析的整个过程中,能做到“不掉进坑里”。而专业的数据分析常见的SAS软件,以及涉及的数据的描述性分析、线性回归分析、典型相关分析等,大家可以通过学习《数据分析方法》等相关课程了解,由于笔者能力范围的原因,无法一并阐述,敬请谅解。
抽样的方法
抽样是从研究的总体中按照合理的随机原则抽取部分单位作为样本来进行观察研究,并根据这部分的抽查样本来推断总体,以达到认识总体的目的的一种调查统计方法。首先我们要明确几个大家潜意识都熟知的概念。
总体:我们研究的对象的全部,也称为全样本。
个体:构成总体的每个成员或者每个研究对象。
样本:从总体中抽取出来的个体组成的集合。
抽样常见的方法一般有四种,分别是随机抽样、系统抽样、分层抽样、整群抽样。
随机抽样是指从总体N个单位中任意抽取n个单位作为样本,使每个可能的样本被抽中的概率相等的一种抽样方式。
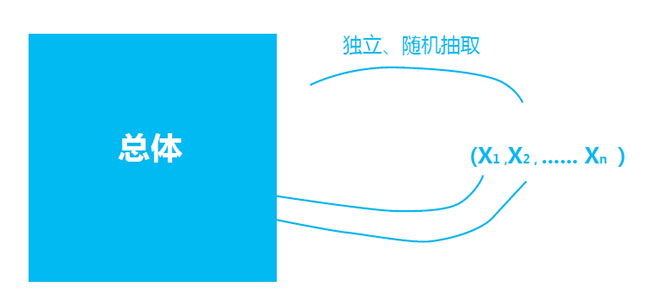
随机抽样只适用于总体单位数量有限的情况,否则编号工作繁重。对于复杂的总体,样本的代表性也难以保证,不能有效利用总体的已知信息等。在市场调研范围有限,或调查对象情况不明、难以分类,或总体单位之间特性差异程度小的情况下采用此法效果较好。
系统抽样类似于随机抽样,但是当个体较多时,随机抽样太过烦琐,因此可以按照预设的规则,从不同的部分中抽取相应的个体。例如假设抽取若干学生检查学习成绩,可以先按照学号编号,然后确定每隔K个编号抽一个。这种抽样方法简单易行,缺点就是容易出现大的偏差。
分层抽样是先将总体的单位按某种特征分为若干次级总体(层),然后再从每一层内进行单纯随机抽样,最后组成一个样本的方法。分层抽样尽量利用事先掌握的信息,并充分考虑保持样本结构和总体结构的一致性,这对提高样本的代表性是很重要的。当总体是由差异明显的几部分组成时,往往选择分层抽样的方法。
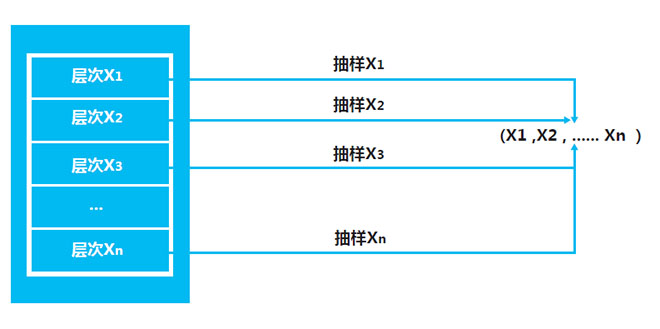
例如研究某高校的就业率情况,我们可以将高校毕业生分为几个类别,分别是博士生、硕士生和本科生,然后将三个层次都进行抽样,即可获得总样本。
分层抽样有两个明显优点:第一就是在不断增加样本规模的前提下降低了抽样的误差,提高了抽样的精度;另一个优点就是非常便于了解总体内不同层次的情况,便于对总体不同的层次或类别进行单独研究。
整群抽样又称聚类抽样,是将总体中各单位归并成若干个互不交叉、互不重复的集合,称之为群,然后对群进行抽样。整群抽样与分层抽样在形式上有相似之处,但实际上差别很大。分层抽样要求各层之间的差异很大,层内个体或单元差异小;而整群抽样要求群与群之间的差异比较小,群内个体或单元差异大;分层抽样的样本是从每个层内抽取若干单元或个体构成;而整群抽样则是要么整群抽取,要么整群不被抽取。例如,调查某地区教师的收入水平,可以直接抽查某一所学校的老师的收入水平,以该校作为当地的样本。
这种抽样方法代表性较差,抽样的误差大。因此,不同子群相互之间差异很大,而每个子群内部的差异不大时,适合使用分层抽样的方法;反之,当不同子群之间差别不大,但每个子群内部差异比较大时,则特别适合采用整群抽样的方法。
抽样方法不一样,会导致结果不一样。但是就算抽样方法一样,不同的研究方式,包括对指标的观察不同,也会导致结果不一样。
再回到上面提到的案例里,如果A网站用户的平均年龄是20岁,B网站用户的平均年龄也是20岁,我们能否得出一个结论:A、B网站的用户基本上都是同一年龄层的?
这不仅仅是抽样的问题,我们还要关注抽样结果的几个指标:众数、中位数和平均值。
众数是指一组数据中出现最多的数据;中位数是指所有数值排列起来之后,处于数列中间的数值;平均值则是所有数据平均之后的数值。
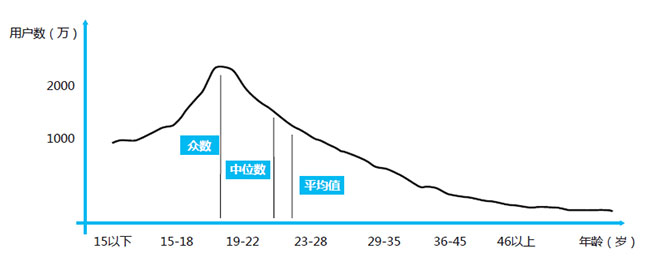
我们讲用户平均年龄是20岁的话,是指平均值为20岁。但是我们并不能得出A、B两站的用户基本是一个年龄层的。因为年龄结构有较为分散的可能,也有高度集中的可能。如果用户的年龄结构较为集中,我们在做运营的时候就要集中精力考虑主要用户,而不用注意其他年龄段的需求;如果年龄结构较为分散,那么我们可能需要考虑所有年龄段的用户的需求。
绘制正确的数据图表
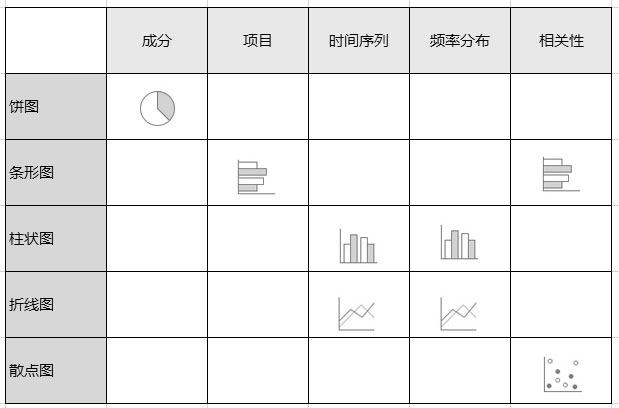
在数据呈现方面,制作以数据为基础的图表,能体现运营人员对数据的理解和专业程度。一般来说,最常见的图表的基本形式有五种:饼图,条形图,柱状图,折线图,散点图。本节将讲述在什么情况下使用这些图表。
一般来说,选择什么样的图表应该由你想要表达什么信息来决定。通过确定需要表达的信息和表达的类型(对应关系),就可以决定用什么样的图表,常见的对应关系如下。
1.成分相对关系,例如:A产品销量占公司总销量50%。
2.项目相对关系,例如:A产品销量相当于B/C销量总和。
3.时间序列相对关系,例如:利润在过去4个季度中逐步上升。
4.频率分布相对关系,例如:大多数快递出货后需要5~6天才能送达。
5.相关性相对关系,例如:与…有关,随…增长,随…而不同,等等。
对应关系使用不同的图表类型如下。
一般来说,我们做饼图的时候,成分应该控制在6种以内,而且最重要的成分应该摆放在12点钟位置,并给予明显颜色突出,其他内容依次顺时针摆放。最简单的饼图能够直接估算出各成分的百分比占比情况,所以不要做得太花哨。
而项目相对关系可以用条形图来表示,条形图的纵向并没有刻度,横向(顶部或底部)可以做一个刻度尺来表示数值大小。目标项目可以用强烈颜色进行突出。
折线图和柱状图都可以描述时间序列。值得注意的是,数据较少时可以用柱状图,数据较多时必须使用折线图。如果有多于两个以上的项目作对比,可以每两个项目做一个折线图,而自己的项目则采用强烈颜色突出该部分。
频率分布相对关系也可以用折线图和柱状图描述。一般来说,垂直维度是项目(频率)的数据(或百分比),水平维度则是各范围的分布情况。我们对水平维度进行控制,选择不同的维度,以便于找出规律曲线。
相关性相对关系可以告诉你两种变量是否符合你的期待。例如:用来验证经验丰富的雇员的销售业绩比经验少的雇员好。如果符合相关性,那么散点图的分布应该在左下角到右上角的对角线附近。
附:常见的数据统计平台
数据分析是一门科学,本章描述的内容仅仅是基础方法论和皮毛,运营者入门时看了能有个大概的了解。了解了这些基础知识之后,面对合作方或者是公司内部进行沟通的时候,就有了讨论的基础,哪怕不懂更深入的统计方法,也可以理解数据背后的逻辑是否存在问题。
事实上,对于中小企业来说,线上已经有非常多优秀的数据统计和分析工具,除非是大型企业,一般也不需要企业自己搭建数据统计平台。对于运营者来说,更重要的是理论跟实际应用相结合,通过大量的基础数据分析和用户调研,用数据来指导自己前进。
下面附上一些常见的数据统计平台。
网站分析工具
谷歌统计:
百度统计: CNZZ: Alexa:www.alexa.com/APP数据平台
APP Annie:
友盟: Flurry:趋势分析工具
百度指数:
谷歌趋势:在线调查工具
麦客:
腾讯问卷: 问卷网:本文节选自《互联网运营之道》一书,由金璞、张仲荣著,电子工业出版社出版。